I processi Markoviani sono processi stocastici che
modellano situazioni in cui la transizione tra stati non è
deterministica, ma probabilistica, ed è caratterizzata dal fatto che la
probabilità di transire in uno stato successivo dipende esclusivamente
dallo stato attuale.
Ad esempio, siano
Antonio e Biagio due giocatori che decidano di giocare con una moneta
particolare, la cui probabilità che esca testa siano p e croce 1-p.
E siano a e b il capitale iniziale di Antonio e di Biagio rispettivamente.
Vogliamo modellare il processo di variazione del capitale di uno dei due giocatori, diciamo A, che può variare tra 0 (caso in cui perde) ad a+b (caso in cui vince).
La situazione è descritta dal grafo di figura 1.
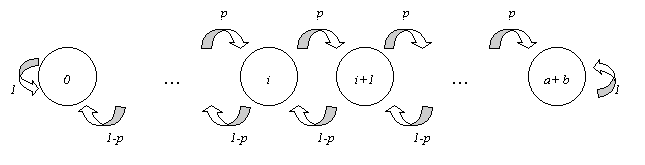
Fig 1: Un processo Markoviano
Il capitale del giocatore A varia dal valore iniziale a a 0 o a+b a passi di 1, incrementando – con probabilità p – o decrementando, con probabilità q=1-p.
Le probabilità di incrementare/decrementare il capitale non sono dipendenti dal numero n di giocate.
In generale, i processi Markoviani sono caratterizzati dalle proprietà che seguono:
·
Rappresentano transizioni tra stati che avvengono in modo probabilistico.
·
Le probabilità di transizione non dipendono dal numero di transizioni effettuate (proprietà di omogeneità).
·
Le probabilità di transizione dipendono unicamente dallo stato attuale (proprietà memoryless, o di assenza di memoria).
Gli oggetti matematici che descrivono i processi Markoviani sono detti Catene di Markov.
Inizialmente,
le catene di Markov sono state utilizzate per prevedere configurazioni
tendenziali di processi Markoviani, come ad esempio l’equilibrio di un
ecosistema. Nell’esempio di figura 1 è possibile prevedere la
configurazione tendenziale della distribuzione di capitale tra i due
giocatori.
In una catena di Markov ad N stati, ove Xn sia la variabile aleatoria che descrive lo stato al passo n-mo, è possibile definire un vettore di distribuzione di probabilità di appartenenza agli stati dopo n transizioni della catena
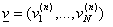
ove
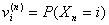
è la probabilità di trovarsi al passo n nello stato i.
Nell’esempio di figura 1, la configurazione iniziale in cui il capitale di A è a, viene descritta dal vettore delle condizioni inziali v = (0, …, 1, …, 0) con un solo 1 in corrispondenza della componente a-esima, questo vettore è detto distribuzione iniziale.
Per sapere qual è la probabilità che A abbia un capitale di c dopo m giocate è sufficiente calcolare il vettore di distribuzione di probabilità v al passo m
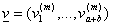
e selezionare la componente
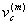
.
Nella
teoria delle Catene di Markov (CdM), che investiga le proprietà delle
catene come successioni di variabili aleatorie, vengono forniti gli
strumenti di calcolo, presentati nel seguito di questo articolo, del
vettore di distribuzione di probabilità, detto misura della CdM.
Esistono
delle misure che, applicate alla CdM, restituiscono sé stesse, ovvero
esistono delle distribuzioni di probabilità che non vengono modificate
dall’applicazione delle transizioni. Queste misure sono dette invarianti.
Il teorema di Markov postula un fatto importante:
·
se Xn
è una CdM a stati finiti e le probabilità di transizione godono di
alcune proprietà di regolarità, allora la CdM ammette una sola misura invariante e tende ad uno stato stazionario.
L’implicazione
del teorema è di vasta portata: le CdM che soddisfano le ipotesi di
Markov tendono ad uno stato stazionario, ovvero la distribuzione
probabilità di converge e convergono ad un valore finito pi tutte le probabilità Pij di transire da uno stato i ad uno j:
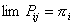
E’ proprio questa proprietà di convergenza delle CdM che le rende
appetibili per l’intelligenza artificiale, in generale per tutti i
processi di riconoscimento.
Una
volta verificato che il problema specifico è modellabile con un
processo Markoviano (che soddisfi le ipotesi del teorema di Markov) è
possibile, infatti, costruire una CdM che converga in modo appropriato.
Un
tipico esempio è il problema del riconoscimento della scrittura, in cui
le lettere vengono disposte in una matrice di punti che viene “ridotta”
a quella della lettera corrispondente. Ad esempio, le lettere
illustrate in figura 2 sono tutte corrispondenti alla A.
|
Fig. 2: Scritture equivalenti del carattere ‘A’ maiuscolo
Nel
processo di riconoscimento la scrittura umana viene mappata in un
vettore di probabilità iniziali. Una lettera viene riconosciuta quando
la CdM converge ad uno stato che rappresenta un carattere.
Il
processo di convergenza può essere modificato assegnando le probabilità
di transizione tra gli stati intermedi mediante un processo, detto training della CdM, in cui si modificano le probabilità di transizione in modo tale da forzare la convergenza al carattere giusto.
Procedimenti analoghi possono essere utilizzati per il riconoscimento di voci, immagini, testi.
Il
seguito di questo articolo espone i risultati essenziali della teoria
sulle Catene di Markov e presuppone un livello di conoscenza di
matematica del primo anno di università per le facoltà
tecnico-scientifiche, e delle basi di Calcolo delle Probabilità e
Statistica.
Definizione – Catena di Markov
Si definisce Catena di Markov (CdM) una successione {XN }di variabili aleatorie (v.a.) discrete in EÌN, ove N è l’insieme dei numeri naturali ed E è detto spazio degli stati contenente tutti i possibili valori di XN, per cui valga la proprietà di Markov di omogeneità:
P(XM+1 = j | XM = iM, …, X1 = i1, X0 = i0) = P(XM+1 = j | XM = iM) = Pi,j
in cui la probabilità di transizione Pij dallo stato i allo stato j in un passo non dipende da M.
Ad esempio, la CdM di figura 1 ha come spazio degli stati E = {1, …, a+b } (N=a+b).
Definizione – Probabilità di transizione in k passi
Pi,j (k) = P(XM+k = j | XM = i)
è la probabilità di transire dallo stato i allo stato j in k passi.
Definizione – Legge, distribuzione o misura di XN
La legge o distribuzione o misura di XN è data dal vettore
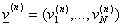
ove
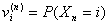
[1]
è la probabilità di trovarsi al passo n nello stato i.
Calcoliamo la [1] applicando la formula delle probabilità totali (
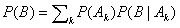
, ove Ak è una partizione dell’universo degli eventi W
![]()
) utilizzando come partizione il valore della v.a. al passo iniziale X0=k, per ogni kÎE:
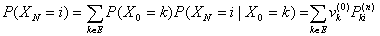
[2]
se definiamo la matrice
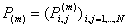
[3]
delle probabilità di transizione tra tutti gli stati di E in m passi, allora l’ultimo termine della [2] diventa l’espressione del prodotto scalare tra il vettore delle condizioni inziali v al passo 0 e la matrice P(m) definita in [3].
Ciò significa che la misura v(m) al passo m è data dal prodotto scalare:
v(m) = v(0) P(m) [4]
Nel definire una CdM, occorre quindi esplicitare anche questi due termini:
1.
La matrice P=P(1)= Pij delle probabilità di transizione tra gli stati i e j in E.
2.
La misura iniziale v(0)
Teorema
P(m)=Pm
Questo teorema consente di calcolare la misura di una CdM al passo m :
v(m) = v(0) Pm [5]
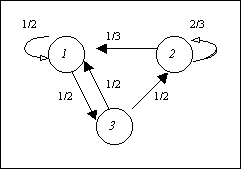
Esempio 2
Sia la CdM di Fig. 3, con E={1,2,3} (N=3) e:
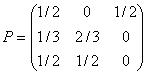
; v(0)=(1/3, 1/3, 1/3)
la legge di X2 è
Fig. 3 Una CdM a 3 stati
v(2) = v(0) P2=(1/3, 1/3, 1/3)
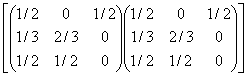
Definizione
Se v(0) = v è tale che v = vP , allora è detto misura invariante.
Teorema (Markov-Kakutani)
Se XN è CdM a stati finiti, allora esiste almeno una misura invariante.
Esistono
condizioni iniziali che non producono variazione del vettore di
distribuzione delle probabilità, il teorema M-K afferma che tutte le
CdM a stati finiti (i.e. con |E| finito) ne hanno almeno una.
Definizione
P è regolare se esiste n t.c. Pn > 0.
La
matrice delle probabilità di transizione in un passo è regolare se
esiste almeno una sua potenza in cui tutti gli elementi sono positivi.
Teorema (Markov)
Se XN è CdM a stati finiti, allora esiste una unica misura invariante
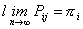
.
Ovvero si ottiene che la legge di distribuzione delle probabilità tende ad un vettore stazionario p:
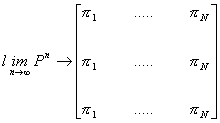
Il vettore delle probabilità stazionarie p si ottiene risolvendo il sistema seguente:
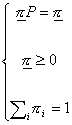
[6]
Nell’esempio 2, il vettore stazionario si ottiene risolvendo il sistema:
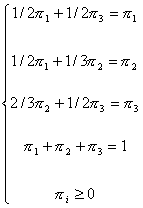
da cui p = (4/11, 3/11, 4/11)